
Julian Brooke and I are very pleased to announce the beta release of GutenTag, our free, open-source, multi-platform, pun-friendly tool for computational analysis in the Project Gutenberg (PG) corpus.
GutenTag does two very exciting things for Digital Humanists. First, it makes it easy to build highly customized literary corpora for large-scale text analysis. Second, it has a sophisticated method for automatically representing the structure of literary texts in the Text Encoding Initiative (TEI) XML format. The GutenTag system is covered in more detail in the poster we presented at the NAACL conference, in the academic paper that introduced it (to a Computer Science audience), and on the main GutenTag website. But here, I’ll expand on the two “game-changing” aspects of GutenTag for literary research.
Building customized literary corpora for large-scale computational literary analysis
After reading a book like Matthew Jockers’s Macroanalysis, you might say to yourself, “Wow, this is fascinating stuff. I’d really like to try it myself!” (Or, alternatively, “Damn, that is truly maddening stuff. I could do a much better job myself.”) There isn’t much stopping you from doing so. Topic modeling tools like MALLET are free and relatively easy to use. Jokers wrote a whole book laying out a DIY method for performing the types of literary computation in Macroanalysis using the programming language R.
But even once you’ve got Mallet and have mastered the basics of R, you’re left with a vexing problem: now that you’re technically equipped to do large-scale literary analysis, you don’t have any texts to analyze. While Jockers was kind enough to write books explaining his methodologies and his findings, he has not released his corpus of thousands of nineteenth century novels; this remains off-limits (perhaps understandably, given how much effort it took to prepare it, and the fact that it is largely derived from text collections that require subscriptions to access.)
One solution is to get texts from the free and publicly available Project Gutenberg. Indeed, in practice, this is what most of us do. The oldest digital library (in existence since 1977, the year that gave us The Clash’s debut LP) PG now has more than 50,000 texts in its collection. Google Books may have more, but you can’t download most of them, and certainly not all at once; Hathi Trust, likewise, has way more, and you can download lots of them, but most are quite “dirty” — filled with OCR errors. Unlike either, Project Gutenberg is human-curated: most of its texts have been typed by hand and verified by humans. 50,000 clean texts are more than enough to get you going in large-scale computational analysis.

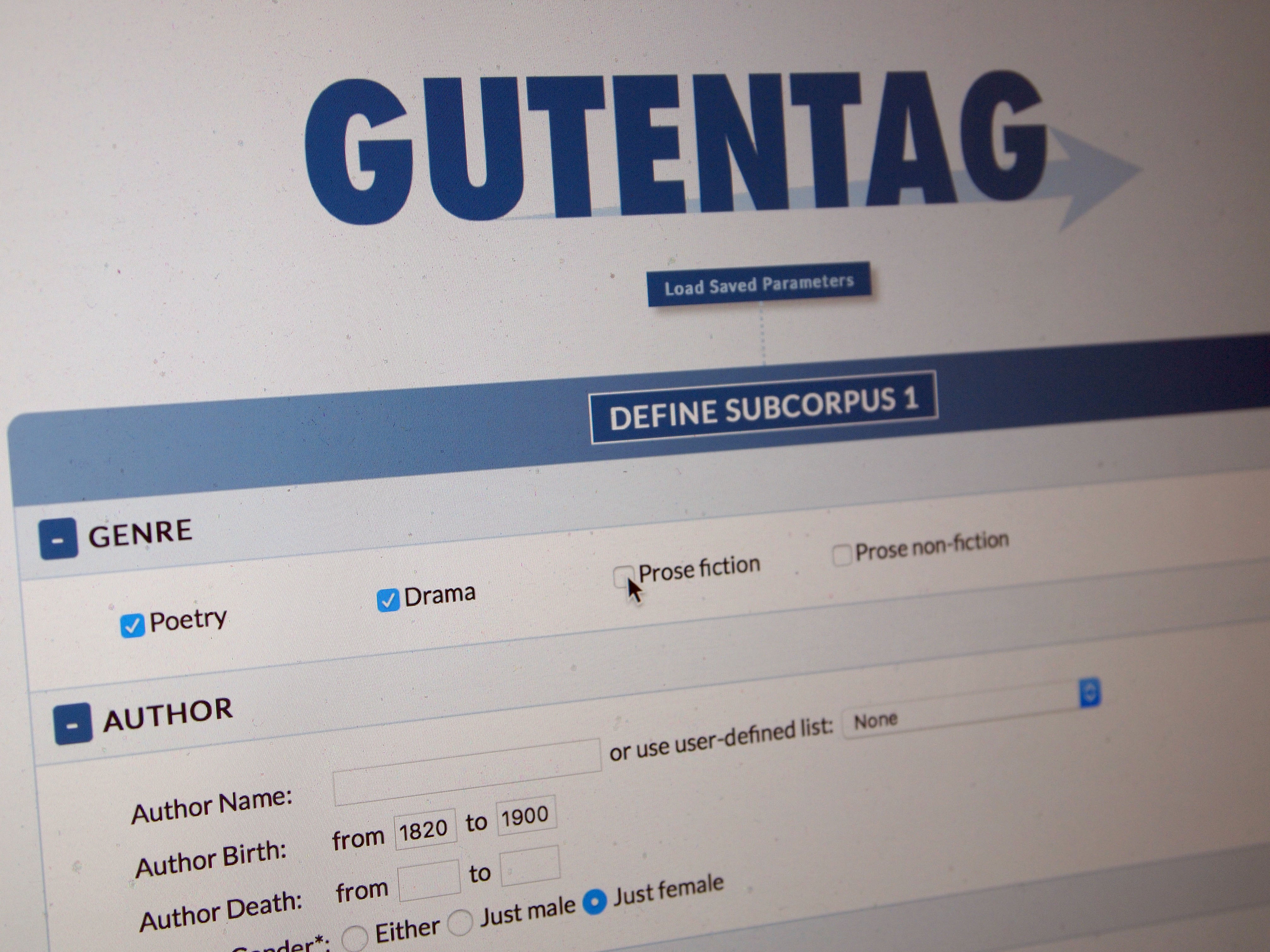
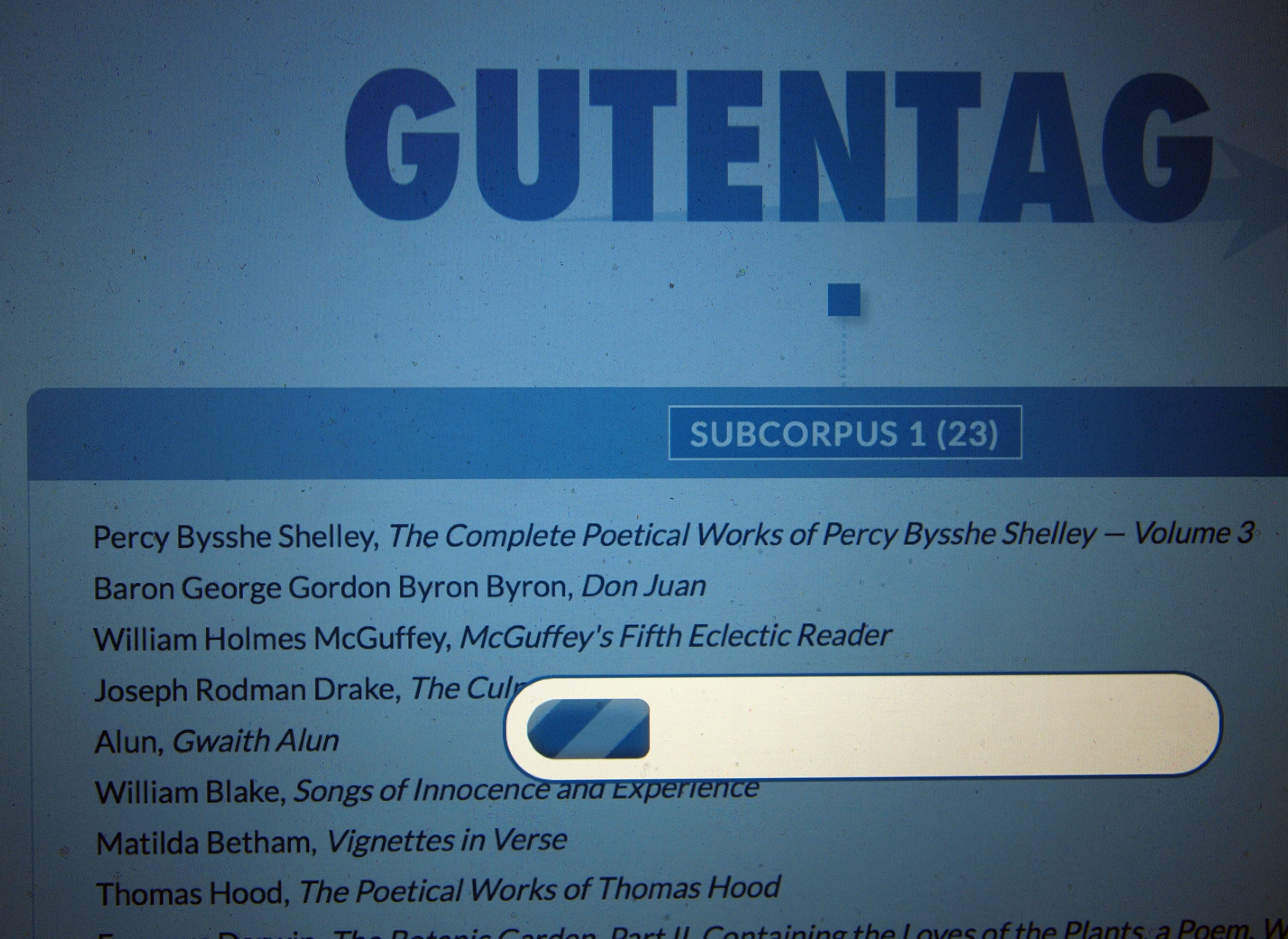
But there’s a problem. Say you want to analyze the nineteenth century English novel. You could go and download the entire 2010 image of Project Gutenberg (comprised of some 25,000 texts, not the full current corpus, but the only currently available bulk download), and you would soon have, on your hard drive, a whole lot of nineteenth century novels. But you would also have many thousands of novels from other periods, as well as many more texts in other genres and indeed in other languages. And let’s say you’re interested in a highly specific grouping of texts: say, poetry by female authors published in England between 1870 and 1880. There would definitely be a lot of texts meeting your criteria among the 25,000 texts you just downloaded. But there is no easy way of sorting them out from the rest.
Faced with this situation, what you’d probably do is manually identify and search for all the texts you can think of that meet your criteria and are in the PG corpus. Then you’d have to go the PG website, search for each of them individually, and save them on your computer. Even after you’d exhausted the limits of your memory, you’d probably only be able to come up with a fraction of the total texts that PG holds that meet your criteria — and you probably wouldn’t have nearly enough to make good use of a technique like topic modeling, which requires millions of words before it begins to produce useful results. Even if you did get enough files, your results would be muddied by the fact that PG files all come with annoying and inessential copyright headers and footers. You’d need to manually remove these from all of your downloaded files.
This is where GutenTag comes in. Our interface allows you to quickly build corpora that reflect the specific needs of your research. If you’re only interested in 17th century drama, we can help you quickly find all the texts meeting those criteria in PG. Likewise if your research interests are in late-nineteenth century female poetry. Our system also removes all that PG copyright information automatically. (NB: GutenTag calls any customized group of texts a “subcorpus,” since PG is the “corpus,” and what you’re building is a specialized subset of that larger corpus.)
There are a few serious drawbacks to our system in its current incarnation. Since we’re working from information that PG itself provides, all we know for sure about texts right now are their authors, their titles, and the the dates of birth and death of their authors. (While this is all we know for sure, GutenTag is good at guessing genres — and in some cases, PG provides Library of Congress classifications.) If you want a seventeenth-century corpus, you have to guess the likely birth and death dates of authors from that period. Likewise, our system for identifying author gender is very, very stupid at the moment: it just guesses based on author first name, and so misses obvious cases like George Eliot. Working on these issues is our first priority as we move forward from our beta release. Our plan is to mine this metadata from sources like Wikipedia, DBpedia. and OpenLibrary. If you want to help, our source code is available.
Automatically-generated structural information in TEI
Let’s say that you’re researching trends in diction in nineteenth-century drama. You’re interested testing the hypothesis that, following the critical dicta of the Romantics, the language of nineteenth-century drama comes closer to representing everyday speech over the century. GutenTag could help you build a large corpus of texts to analyze for your project. But it can help in another way, too.
For your research, you need to be able to separate character speech from all the other sorts of text present in the PG editions of nineteenth-century drama. Front matter little title pages and introductions and character lists aren’t relevant to your research question. Back matter like indexes and afterwords aren’t either. Even within the main body of the play, you would need exclude many things to perform your analysis: scene and act headers, stage directions, character names, descriptions of the setting, and so on.
PG offers no in-built method of making these distinctions: its editions contain no explicit markers identifying structural features of literary texts. To pull out only character speech and ignore the rest, as such, would require you do manually edit each file you download. For a large-scale investigation such as yours, this is obviously impractical.
GutenTag, however, is able to make such distinctions. Using standard TEI tags, it can reliably identify the major structural elements of a variety of literary genres. These include:
- For all genres, distinctions between front matter (title pages, introductions, prefaces, chapter lists, etc.), the main body of a text, and back matter (epilogues, indexes, endnotes, etc.), as well as any persons named in the text.
- For fiction and non-fiction, divisions of chapters and parts.
- For fiction, distinction between narration and character speech, as well as the identify of the character speaking every speech.
- For poetry, boundaries of individual poems, and, within poems, lines, stanzas, and parts/cantos.
- For drama, act and scene boundaries, cast lists, speaker names, setting descriptions, and stage directions.
Having this structural information in an explicit, machine-readable format like TEI XML allows you to pull out only what you need when performing your analysis. (Working with TEI files in this way requires some programming skills — but so does most advanced literary analysis, and working with XML is quite easy in all programming languages.)
GutenTag identifies these features using a flexible rule-based system that is able to take into account the inconsistent means of identifying structural features in PG texts. It is not perfect — indeed, in some weirdly-formatted PG texts, it is very far from perfect — but it performs quite well, and with input from the DH community we hope to have your help in making it better. Given the immensely labor-intensive nature of manual TEI encoding, we believe it opens exciting avenues for large-scale text analysis that have simply not existed before.
Using GutenTag
GutenTag does much more than this. For instance, it include a whole “Analysis” module that allows you to perform your analysis within the GutenTag system, without having to export any files. The modular nature of GutenTag means that these parts of the system can be easily expanded, even if they are relatively threadbare at the moment. For now, though, I think most early users will rely mostly on GutenTag’s export features.
GutenTag is available for download at http://www.projectgutentag.org. Full instructions are available there, as well as in the Readme file on the GutenTag Github page.
Update: GutenTag is now available in an entirely web-based version.