
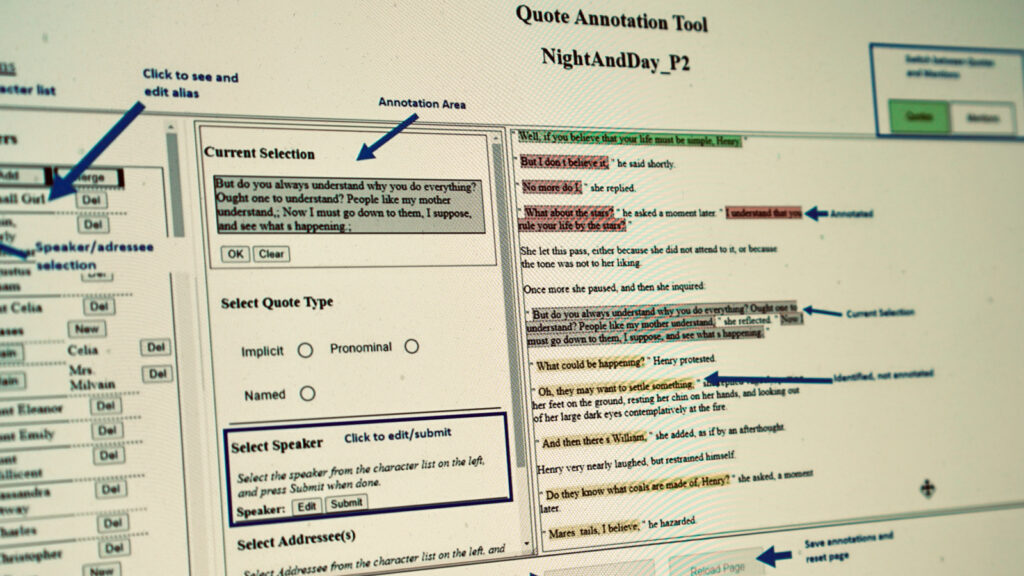
The Project Dialogism Novel Corpus (PDNC) is a dataset for the computational analysis of novels. The PDNC currently consists of over 20 novels in which all quotations are identified and annotated for speaker, addressee(s), and characters mentioned. PDNC is by an order of magnitude the largest corpus of its kind. Each novel is annotated manually by a pair of annotators using customized software we developed.
The dataset can be found in the following GitHub repository: https://github.com/Priya22/project-dialogism-novel-corpus
The project’s Annotation Guidelines can be accessed here.
We introduced the dataset to a computer science audience in this LREC2022 paper and to a humanities audience in this paper presented at the Digital Humanities 2022 conference (forthcoming).
PDNC is co-led by myself, Krishnapriya Vishnubhotla (Computer Science, University of Toronto), and Graeme Hirst (Computer Science, University of Toronto). The annotations have been provided by a tireless and indomitable team of student annotators since the spring of 2020.