

For the first time in my life, I’m teaching a programming class for English students. There have been a few bumps in the road, but all in all, it’s been pretty awesome. My students make me proud every class, not only figuring out stuff they thought they had no business figuring out, but doing incredible, weird, amazing, totally unexpected things with their newfound programming skills.
We’ve been using Nick Montfort’s textbook, Exploratory Programming for the Arts and Humanities (MIT Press, 2016). While it’s mostly been a good guide, there have been a few times where I could feel my students itching for examples and projects that are more specifically literary — not just things to please students from all the many branches of “the arts and humanities.” When that happens, we take a break, read some DH-heavy literary theory, read some computational literary texts (thank you Emily Short!) — and focus on some more obviously English-y task. In our first such break, we made madlibs. In our second break, we made rudimentary text adventure/Interactive Fiction games. In our most recent break, we made Twitter bots.
I really love Twitter bots. First and foremost, they’re awesome because they’re on Twitter — someplace “real,” not just stuck in the hermetic confines of the iPython Notebook or a Terminal window. Students — and, let’s face it, me too — get really excited when they see that something they created in a programming environment shows up in a part of the online world that they’re actually familiar with. I really love that Twitter allows bots, for this reason. Twitter, if you’re reading this: Thank You. It would be really easy to block bots, but you don’t. By being awesome in this way, you are giving English students a reason to learn programming.
Other things I love about Twitter bots? They participate in a venerable literary tradition, the tradition of text generation. As Nick Montfort writes in Ch. 1 of Exploratory Programming, literary text generation goes all the way back to the early days of computation. He provides some nice archeologically-unearthed samples from the 1950s and 60s — think about it, this was happening while Elvis was King — at his Memory Slam page, including an example I’ll get back to at the very end of this post, Brion Gysin and Ian Sommerville’s “Permutation Poems.” And before computational text generation, we had analog text generation like Dada découpés. With very few exceptions, the best and most popular bots on Twitter (like the hilarious Magical Realism Bot) are text generators.
There is lots of great information on the web about how to make text generators and how to make Twitter bots. But, as usual, I find that this stuff isn’t always written for English Lit people, and can be a little hard for us to follow. So here’s a tutorial for us.
Everything below is written in Python. It assumes you know the super-basics of Python, but not a whole lot more.
I’ve broken this guide into five sections:
1. Making a Simple (and Stupid) Text Generator
Before we can even think about posting anything to Twitter… we need something to post to Twitter. Since any one of us can log into Twitter and post things in the normal human way, we’ll want something that is abnormal and a little non-human. What better than a simple text generator?
Here’s about the simplest example I can think of. You start by defining a bunch of lists of words, then use randomness to combine them so as to make unexpected sentences. You could probably do this by jumbling some pieces of paper up in a hat, Dada-style, but this is a little easier, and definitely more 21st century. As I will throughout the tutorial, I’ll show you all the code, then I’ll explain it step by step. Full code for the text generator follows.
preamble = ["When I'm being threatened with certain death", "Generally speaking, when a panda is pursuing me at high speed", "Every second Thursday", "Sometimes, after a long hard day", "Whenever there's a full moon"]
action = ["kick back with", "play air guitar to the tune of", "take a moment to reacquaint myself with", "hang ten on", "stare longingly into the eyes of", "give a very firm handshake to"]
adjective = ["a cold", "a big", "a burly", "a hairy", "an exquisite", "an impetuous"]
noun = ["beer", "surfboard", "book", "pair of scissors", "inanimate carbon rod", "pillow", "airplane", "french bulldog"]
import random
def sentencemaker():
return random.choice(preamble) + ", I like to " + random.choice(action) + " " + random.choice(adjective) + " " + random.choice(noun) + "."
It’s only a few lines of code, but — trust me — it generates sentences funny enough to keep your Twitter followers laughing for weeks. Here’s how it works.
Before I started, I decided that I wanted to make sentences something like this:
[Every now and then], I like to [kick back] with a [cold] [beer].
My sentence would start with some kind of preamble, then have the words “I like to,” then have some kind of verb or action, then have the words “with a,” followed by an adjective (or adjectival phrase) and a noun. But the key thing is that each part of the sentence would be chosen randomly from a list so that, when they were all stuck together, I would get something unexpected.
Since I have four parts of my sentence that need to be “generated” randomly (a preamble, an action, an adjective, and a noun), I need four variables. For each of these variables, I need to define a bunch of different possibilities. It doesn’t matter at all how many possibilities there are — there could be one (though that would be boring) or there could be a million (though that would require a lot of typing). I just wrote in as many as I could think of before I got bored. The Python data type that makes the most sense for this application is a list (specifically, a list of strings), so that’s what I chose.
Defining these four lists is most of the actual code. Careful where you put your commas. If you’re British, you’re loving this. If you’re American or Canadian, you’re totally violating MLA conventions, and that hurts. But learning new things hurts. So there’s that consolation.
preamble = ["When I'm being threatened with certain death", "Generally speaking, when a panda is pursuing me at high speed", "Every second Thursday", "Sometimes, after a long hard day", "Whenever there's a full moon"] action = ["kick back with", "play air guitar to the tune of", "take a moment to reacquaint myself with", "hang ten on", "stare longingly into the eyes of", "give a very firm handshake to"] adjective = ["a cold", "a big", "a burly", "a hairy", "an exquisite", "an impetuous"] noun = ["beer", "surfboard", "book", "pair of scissors", "inanimate carbon rod", "pillow", "airplane", "french bulldog"]
Okay, once that’s done, we need to do some actual programming. But it’s all very simple.
First, I need to import Python’s “random” module, which deals with — surprise! — randomness. This module is built in to Python, but by default it’s switched “off,” because not everyone needs to use randomness for every script they write, and it takes up memory when it’s turned on. Anyway, we need it, so we’re turning it “on,” which is what this line of code accomplishes:
import random
Why do we need the random module, you may ask? Because our whole program depends on the ability to randomly choose items from lists. Our text generator is going to work as follows:
- Randomly pick one of the preambles
- Stick that together with the words “, I like to”
- Randomly pick one of the actions, then stick it on the end of our ever-expanding string of text
- Paste in the words “with a”
- Randomly pick one of the adjective, and paste that in
- Randomly pick one of the nouns, paste that it
- Close things off with a period.
That’s our algorithm. Relatively simple, right?
As you can see, randomly picking one of x, is something we need to do a lot of. Thankfully, Python’s random module has exactly the tool we need: random.choice(). It’s a function, and it works as follows: when you feed it a list, it returns one of the items from the list, chosen at random.
The seven-step “algorithm” described above looks like this in Python code:
random.choice(preamble) + ", I like to " + random.choice(action) + " " + random.choice(adjective) + " " + random.choice(noun) + "."
All we need to do is pass our pre-defined list variables as arguments to the random.choice() function, and it spits out a randomly-chosen item from each. In this example, we’re using the + sign to stick all the bits of text (strings) together — the randomly-chosen bits and the hard-coded bits like “, I like to “.
The final step is to wrap all this up into a function of our own. Here’s how it looks:
def sentencemaker():
return random.choice(preamble) + ", I like to " + random.choice(action) + " " + random.choice(adjective) + " " + random.choice(noun) + "."
Here we’ve made a very simple new function all of our own, named sentencemaker(). It takes no arguments, but every time it’s called, it returns a (hopefully) hilarious sentence, jumbling together all the parts we came up with. For example, running that code in the iPython Notebook, just now, I got this output.
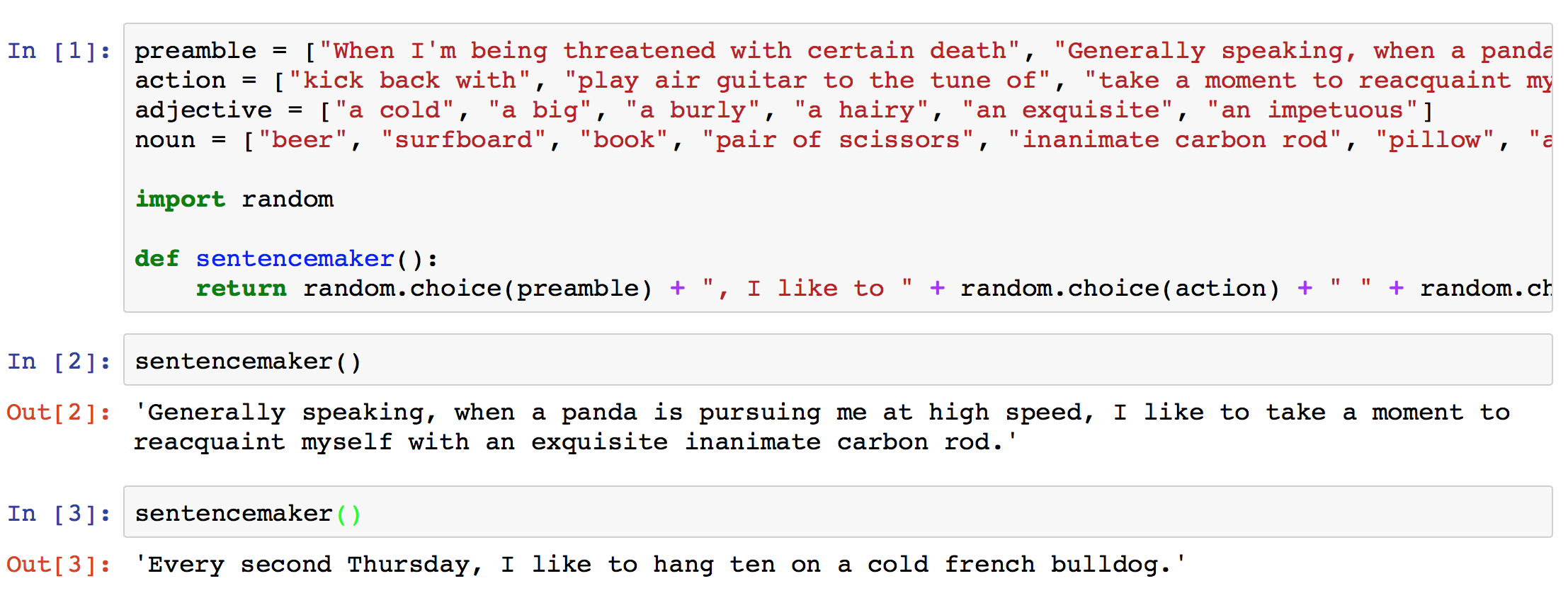
Which is at least slightly funny. Notice how each time I call sentencemaker(), I get a different output. That’s what I want. That’s how I know it’s working. If you get the same output every time you call sentencemaker(), something’s up — things just aren’t sufficiently random.
2. Setting Up a Twitter App
So, awesome. Using only 7 lines of code (by my count: remember, I’m an English professor), we’ve made a little machine that can generate funny, weird, or otherwise interesting bits of text. (And you can make much better ones than this, with only a little more code. Instead of four variables, make 10; for each, make 10 different possibilities or more; then stick them together in totally unexpected ways. My safe out is that I made something deliberately stupid and flimsy to inspire you to make something better yourselves.)
But we have a problem. Yes, Python will now spit these funny phrases into the iPython Notebook window — or, if copied into a .py file, into the Terminal window. But we don’t want our funny phrases to just live in these drearily secluded spots. We want the world to see them! We crave the adulation of the masses! We need them to show up on Twitter.
Bless the people at Twitter, who make it relatively easy to post our funny phrases there instead of just on our lonely computers. Relatively easy, but still a bit of a pain. Here’s what you need to do.
First, you need to create a Twitter account. If you already have a Twitter account, you’ll want to make a new one. Your bot is going to be spewing out all sorts of nonsense, and who knows what it might say. Plus, it has its own personality, and it wants some breathing space. Better to give it its own account.
Go do that. You don’t need me to show you how. One thing I will tell you to do, though, is to be sure to provide a cell phone number when you sign up. You’ll need a phone associated with your account for this all to work. Okay, go do that, and I’ll be waiting here for you.
Okay, you’re back: you have a new Twitter account, you’ve struggled for hours to find a decent handle that hasn’t already been claimed by some other obnoxious bot-maker (sorry, folks, @LilPythonBaby is taken, and so is @Gysinner), and you’re ready for the next step.
For this step, you will need my help. Now you’re going to make a “Twitter app.” It’s amazing that Twitter allows us to post directly from Python (or any number of programming languages) — but in order to do so, we need to first sign up for special access. It’s probably worth pausing to note that what we’re asking for access to is the “Twitter API,” an API being an “Application Programming Interface.” We’ll just think of it as the magical thing that allows us to send stuff to Twitter straight from our programming environment — i.e., from Python.
So, yes, we need to register our Twitter bot as a “Twitter app.” This happens at https://apps.twitter.com
You’re probably already logged in to the Twitter account you just created, but if not, log in. Then click on the big friendly “Create New App” button.
On the next screen, it asks for a name, description, and website for your “app.” None of this is very important, and if your bot doesn’t have a website (which I’m guessing it doesn’t), just put in whatever, like I did here. Twitter doesn’t seem to mind.
Now just agree to the terms of service and click “Create your Twitter application.” (If you didn’t associate a phone number with your account above, you’ll need to do that now.)
If you made it to the next page, you now have your Twitter App. Congratulations!
Now we need to get all the secret passwords to actually allow us to log in to our Twitter account from Python. These passwords are found under the “Keys and Access Tokens” tab, which you can see on the above page. Click on that, and you’ll see something like the below, but without all the fuzzed-out passwords.
Right up at the top of the page, you’ll see “Consumer Key (API Key)” and “Consumer Secret (API Secret),” both with long crazy passwords next to them. Copy those both down somewhere — for instance, into an open text file. You’ll need them.
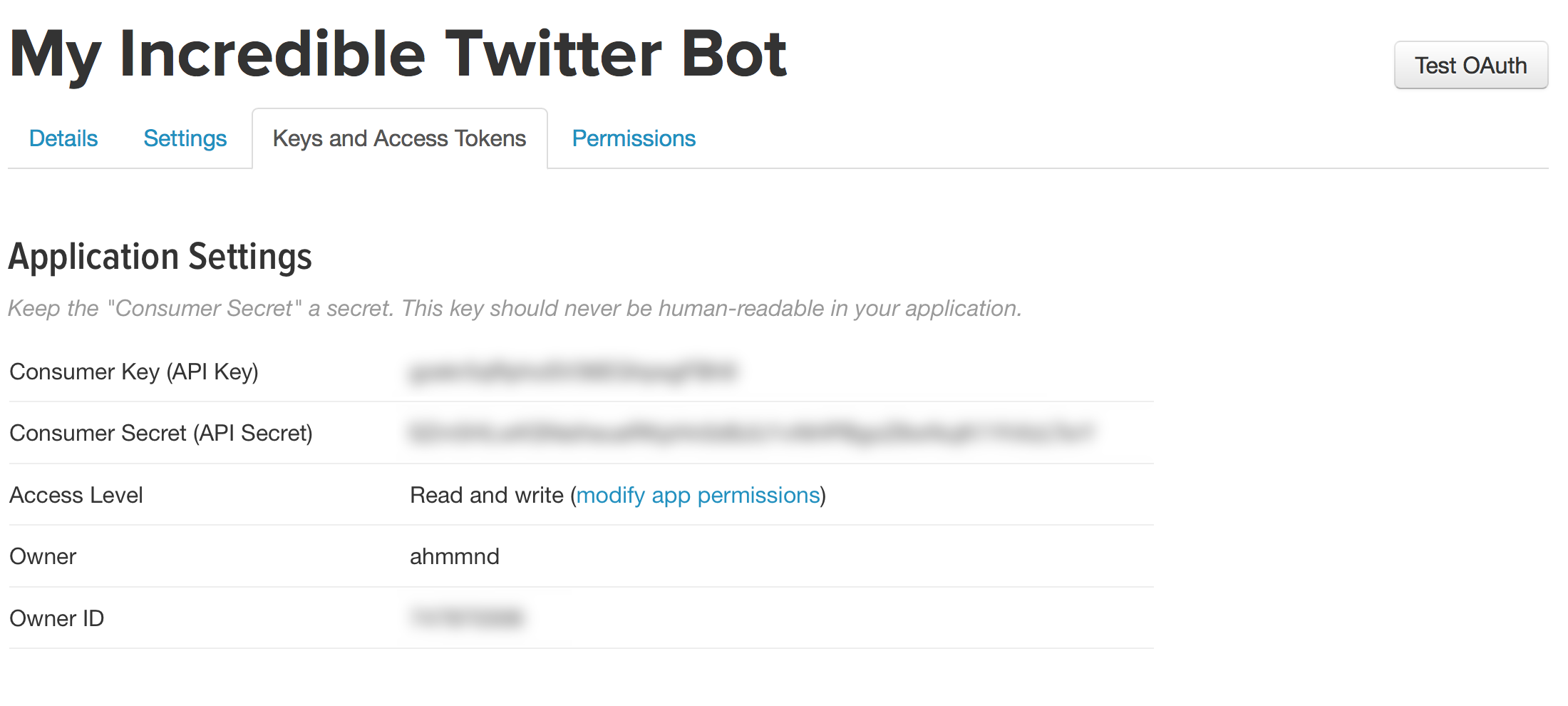
Alas, two incredibly long passwords just wouldn’t be enough, would they? You also need two more! Scroll down a bit on that page and, under “Token Actions,” click “Create my access token.” That will reload the page. Scroll back down, and you’ll see something like this:
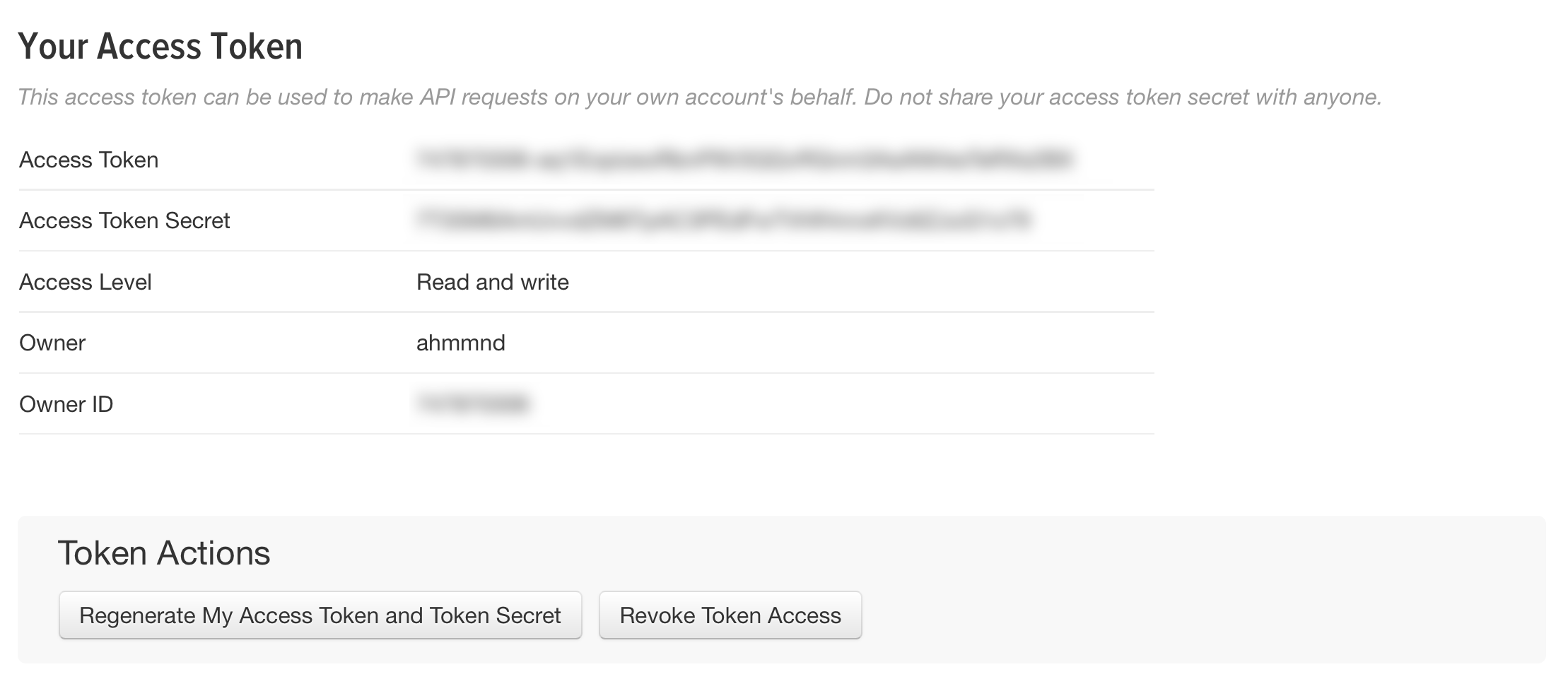
Same deal: this time you want to copy your Access Token and your Access Token Secret into that text file, or whatever.
Okay, take a deep breath. Your Twitter app is all ready to connect with Python. So now we just need to get Python to connect to it.
3. Connecting to Twitter with Tweepy
Fabulous: we have a text generator capable of producing Twitter-worthy weirdness, and we have a Twitter App all set up and ready to post said weirdness. Now we just need to be able to connect to our Twitter App via Python, and pass our hilarious generated sentences into Twitter from there.
For this, we rely on a module called Tweepy. Like random, Tweepy is a module. Unlike random, Tweepy does not come pre-installed in Python. This means we need to download it in order to make use of it. In order to download Tweepy, head to the command line, and type the following:
pip install tweepy
If that didnt’t work, it means you don’t have pip (the Python package manager) installed. Instructions for getting it installed are here. Once it’s installed, try that line again.
Assuming that’s done, we’re not at all far from a fully-functioning Twitter bot. Indeed, here’s the entirety of the code we need to make ours run. As above, I’ll give you everything, then work through it step by step.
import random, time, tweepy
preamble = ["When I'm being threatened with certain death", "Generally speaking, when a panda is pursuing me at high speed", "Every second Thursday", "Sometimes, after a long hard day", "Whenever there's a full moon"]
action = ["kick back with", "play air guitar to the tune of", "take a moment to reacquaint myself with", "hang ten on", "stare longingly into the eyes of", "give a very firm handshake to"]
adjective = ["a cold", "a big", "a burly", "a hairy", "an exquisite", "an impetuous"]
noun = ["beer", "surfboard", "book", "pair of scissors", "inanimate carbon rod", "pillow", "airplane", "french bulldog"]
def sentencemaker():
return random.choice(preamble) + ", I like to " + random.choice(action) + " " + random.choice(adjective) + " " + random.choice(noun) + "."
CONSUMER_KEY = 'Your Consumer Key'
CONSUMER_SECRET = 'Your Consumer Secret'
ACCESS_KEY = 'Your Access Token'
ACCESS_SECRET = 'Your Access Token Secret'
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_SECRET)
api = tweepy.API(auth)
while True:
postthis = sentencemaker()
if len(postthis) <= 140:
api.update_status(status=postthis)
print postthis
time.sleep(3600)
That’s it: an end-to-end Python script for a Twitter bot that will run forever and delight the masses. When I showed this script in class, one of my students said, “I always thought people who made Twitter bots and stuff were really smart. But they’re not! It’s so… easy!” Precisely! (But now that you’re making your own Twitter bot, you do feel sorta smart, don’t you? And you’re planning to lord this over your other English Lit friends, aren’t you? I thought so. Me too!)
If you wanted to actually run this script, you could just copy all the above code into a text editor, enter the information for your Twitter App (as described below), and then save the file as something like “amazingbot.py” and run it from the command line. It would then just run and run and run until you told it to stop.
Anyway, it’s a nice, short little script, but that doesn’t mean it’s all self-evident. Let’s break it down part by part and figure out exactly what’s happening.
The first line of code imports some modules. (I moved this up from the previous text generator script; it’s more normal to import modules in the first line of code.)
import random, time, tweepy
We already know random, and we know why we need it. We haven’t actually imported tweepy yet, but we know what it is, and we’ve downloaded it, and we have a sense that we need it to post to Twitter. The time module is new to us. We’ll see what it’s for down below.
The next bit of code is stuff we already know: it’s everything we did in Part 1 to build our text generator. We need it in our Twitter bot script because it’s going to be generating the individual tweets we want to post!
preamble = ["When I'm being threatened with certain death", "Generally speaking, when a panda is pursuing me at high speed", "Every second Thursday", "Sometimes, after a long hard day", "Whenever there's a full moon"]
action = ["kick back with", "play air guitar to the tune of", "take a moment to reacquaint myself with", "hang ten on", "stare longingly into the eyes of", "give a very firm handshake to"]
adjective = ["a cold", "a big", "a burly", "a hairy", "an exquisite", "an impetuous"]
noun = ["beer", "surfboard", "book", "pair of scissors", "inanimate carbon rod", "pillow", "airplane", "french bulldog"]
def sentencemaker():
return random.choice(preamble) + ", I like to " + random.choice(action) + " " + random.choice(adjective) + " " + random.choice(noun) + "."
Now, the next little bit is all new. Also, it’s a little mysterious — but that’s okay. This is the part where we use Tweepy to connect us to Twitter. We don’t need to understand in perfect detail how everything works — we just need to know how to make it work for us. (That’s sort of the trade-off in using a module like Tweepy — it makes things easy, at the expense of making it a little vague what is actually is going on behind the scenes.) Anyway, here’s what we need to do.
CONSUMER_KEY = 'Your Consumer Key' CONSUMER_SECRET = 'Your Consumer Secret' ACCESS_KEY = 'Your Access Token' ACCESS_SECRET = 'Your Access Token Secret'
These four lines are where you put in all those secret passwords you copied off the Twitter App website. Each of these lines creates a variable whose value is one of your many passwords. You need to REPLACE each of the values in quotation marks with your actual, personal passwords. Just copy in the stuff from the Twitter App page: where it says ‘Your Consumer Key’, copy in your consumer key, and so on. Make sure that you do wrap your passwords in quotation marks (single or double, it doesn’t matter). Make sure not to share these we other people, or your Twitter app risks being hacked, and we all know where that leads.
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) auth.set_access_token(ACCESS_KEY, ACCESS_SECRET) api = tweepy.API(auth)
These three lines are where Tweepy does its mysterious magic to connect you to Twitter. I don’t know how it works, exactly, and you definitely don’t need to. Just make sure that these lines of code are in your script, totally unaltered. (You can see that the first two lines use the passwords you provided to authorize you with Twitter.)
Once you’re connected to Twitter, there’s not much left to do. Just a few lines of code.
while True:
postthis = sentencemaker()
if len(postthis) <= 140:
api.update_status(status=postthis)
print postthis
time.sleep(3600)
Line one sets up a while loop, and the specific condition, while True, just means that this loop will run forever, never stopping. Since we want our bot to always be running, we need this infinite loop. (Of course, we can always stop our bot script in the Terminal by hitting control-C.)
Line 2 calls sentencemaker() — the function we made to house our text generator — and sticks its output into a variable called postthis. As you’ll remember, sentencemaker() will return a different sentence every time it’s run, since it depends on randomness to generate text. So every time through the loop, postthis is going to have a different value stuck into it. That’s what we want, since we want our bot to always post some new hilarious phrase, so as not to bore our followers.
The next line is an if statement, saying only proceed if the length of postthis — our would-be tweet — is equal to or less than 140 characters. You can imagine why this is: as we all know, the First Rule of Twitter is that Twitter will only accept tweets of 140 characters or less. If our tweet happens to be longer than that, and we try to post it to Twitter, we will get an error message and our script will crash. We don’t want that — we want it to run forever, unsupervised, glorious, free — so we’ve set up this if statement. If the tweet is longer than 140 characters, our script just loops back to the top of the while loop and tries again with the next randomly-generated sentence. If sentencemaker() returns a sentence of a Twitter-friendly length, though, we proceed to the next level of indentation.
Line 4 up there is where the magic really happens, and our message is posted to twitter. Who knows exactly what’s happening, but this is the syntax that Tweepy needs to see to post something to Twitter:
api.update_status(status="Whatever is here is what you will actually see posted on Twitter.")
As you can see up there, whatever you pass into status= is what will actually appear on Twitter. In our case, we’re passing in postthis (status=postthis), which contains the output of sentencemaker(), i.e., the thing we want to tweet. Then, in line 5, we print that to the terminal, too, so we know we’ve posted something if we’re watching in a console window. Perfect!
By now, the most important stuff is done! But without the ensuing line of code, it would just plow through the while loop, relentlessly posting sentences as quickly as it could, which is very very fast, many times per second, and both annoying our followers with millions of tweets, and pissing off Twitter and causing us to get booted from our connection. So we need a few more lines of code to allow our bot to chill out a little between tweets.
This pause happens in line 6 up above, which uses that “time” function I mentioned before. This line is the reason we imported the time module. The way that time.sleep() works is that you pass it an integer, and it pauses your script for that many seconds. In this case, I’m passing 3600, the number of seconds in an hour. Every time my bot posts a tweet, it then takes a one-hour nap before returning to the top of the while loop. My bot’s followers can expect a tweet once an hour until… infinity. (Worth noting: whenever you put your computer to sleep, time stops counting. It’s sort of comforting to put your laptop to sleep every night and know that your bot will be getting a bit of a rest, too. Also, as I mentioned above, you can always stop your script by hitting control-C in the Terminal window where it’s running.)
That’s it! That’s all you need to do to make a bot. In the next tutorial, I’ll show you how to integrate replies into your Twitter bot, so that people can send it messages and it can reply to them. But by this point, we’ve already done the most fun part, and there is no shame is calling it a day. If you’ve followed my script directly, this is part where you’ll want to make up your own sentence structure, put in your own words… and then set your bot loose on Twitter.
4. Dealing with Replies
Okay, looks like you’re hungry for a bit more, so let’s add one more little wrinkle and figure out what to do if we want to allow our bot not merely to post but also to reply to messages. Things get quite a lot more complicated here, and the added functionality is pretty marginal — but if you’re in the mood, follow along. (Warning: having now actually written this section, it is loooooooooong. Brace yourselves.)
For my example here, I want to implement some pretty simple behaviour. I want my bot to do what it’s already doing, and post a funny tweet every hour. But now, I also want to be able to see if anyone has sent me an @-reply and, if so, write that person a customized message. For this example, I’m going to integrate this reply functionality directly into my bot script. Now, after taking its one-hour nap, my bot will first check for any @-replies, then reply to them (if there are any), and then make its post. My bot’s life will look like this:
- Load up.
- Check for @-replies and reply to them.
- Post another funny sentence.
- Nap for an hour and return to step 2, ad infinitum.
Here I’ll once again post in the complete code, and then we’ll break it down section by section.
import random, time, tweepy, re
f = open("doneupto.txt","r")
doneupto = f.read()
doneupto = int(doneupto)
f.close()
preamble = ["When I'm being threatened with certain death", "Generally speaking, when a panda is pursuing me at high speed", "Every second Thursday", "Sometimes, after a long hard day", "Whenever there's a full moon"]
action = ["kick back with", "play air guitar to the tune of", "take a moment to reacquaint myself with", "hang ten on", "stare longingly into the eyes of", "give a very firm handshake to"]
adjective = ["a cold", "a big", "a burly", "a hairy", "an exquisite", "an impetuous"]
noun = ["beer", "surfboard", "book", "pair of scissors", "inanimate carbon rod", "pillow", "airplane", "french bulldog"]
def sentencemaker():
return random.choice(preamble) + ", I like to " + random.choice(action) + " " + random.choice(adjective) + " " + random.choice(noun) + "."
CONSUMER_KEY = 'Your Consumer Key'
CONSUMER_SECRET = 'Your Consumer Secret'
ACCESS_KEY = 'Your Access Token'
ACCESS_SECRET = 'Your Access Token Secret'
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_SECRET)
api = tweepy.API(auth)
while True:
twts = api.search(q="@LilPythonBaby", since_id=doneupto)
for t in twts:
if re.search("^@LilPythonBaby", t.text):
quoted = re.sub("^@LilPythonBaby ", "", t.text)
replyname = t.user.screen_name
reply = "@" + replyname + ' You say "' + quoted
if len(reply) > 121:
reply = reply[:118] + "..."
reply = reply + '" but I say "MEOW!"'
api.update_status(status=reply)
print reply
doneupto = t.id
f = open("doneupto.txt", "w")
f.write(str(doneupto))
f.close()
postthis = sentencemaker()
if len(postthis) <= 140:
api.update_status(status=postthis)
print postthis
time.sleep(3600)
Much of this is the same, but there are a few new things, and a few of them are a little tricky. Let’s take them one by one.
import random, time, tweepy, re
The opening line is pretty familiar, except that we’re adding one more module, re, for using regular expressions (more on this a little further down).
The next part is probably the major thing to wrap your head around. The reason for these lines is pretty simple, so I’ll state that up front. Basically, we need to know which messages we’ve already replied to. If we didn’t know this, we’d end up replying to every single message that had ever been sent to us every time we moved through the while loop. Luckily for us, Twitter tells us the “ID” of every @-reply we receive, and these are ordered chronologically, so that if we’re somehow able to store the ID of the latest tweet we’ve already replied to, the next time we go looking for tweets, we can be sure to only look at tweets more recent than that one.
But where to store this? Normally, we’d just want to store it in a variable, the place that we normally store things in Python. But what if our program crashes — or we need to restart our computer — or we need to interrupt the script (control-C!) to make some change to our code. These things are not really “what ifs?” — they will all happen sooner or later, and probably sooner than later. And if we’re only storing the ID of the latest tweet we’ve replied to in a variable, it’s going to disappear whenever any of the above situations happen. Meaning that every time we re-start our code, everyone who has ever sent us an @-reply is going to get another response from us. Very annoying. We don’t want that to happen.
What is the solution? Don’t just store it in a variable; store it on your hard drive. In this case, we’re going to store the ID of the latest tweet we’ve replied to in a text file called doneupto.txt which we’ll put in the same folder as our Twitter bot script. Every time we reply to a tweet, we’ll diligently record its ID by writing it to our hard drive in the doneupto.txt file. Then, if (I mean, when) our program crashes, all we need to do it load that magic number from the text file, and all will be well.
That’s what the following lines do.
f = open("doneupto.txt","r")
doneupto = f.read()
doneupto = int(doneupto)
f.close()
These lines do nothing more complicated than open doneupto.txt, read its contents (which is only going to be a single number, but which will be imported into Python as a string), and then convert that number to an integer and stick it into the variable doneupto. Then we close the file.
Note that the very first time you run your fancy, tweet-replying script, your script is going to go looking for doneupto.txt, and if it doesn’t find anything, it’ll crash. So what do you do? Create a plain text file called doneupto.txt, of course! And what do you put into it? Well, since you haven’t replied to a single tweet yet, make its contents the single digit 0. You’ll only need to do this once. For the rest of its life, your script will manage this on its own.
(Yes, Python nerds, there are definitely better ways of doing this, but we’re not Python nerds over here, and we’re just trying to bring our literary creations to life, not make the flashiest code imaginable. So just relax.)
Okay, after that complicated little side-trip, we’re back to a whole wack of very familiar code. You already know all this stuff:
preamble = ["When I'm being threatened with certain death", "Generally speaking, when a panda is pursuing me at high speed", "Every second Thursday", "Sometimes, after a long hard day", "Whenever there's a full moon"] action = ["kick back with", "play air guitar to the tune of", "take a moment to reacquaint myself with", "hang ten on", "stare longingly into the eyes of", "give a very firm handshake to"] adjective = ["a cold", "a big", "a burly", "a hairy", "an exquisite", "an impetuous"] noun = ["beer", "surfboard", "book", "pair of scissors", "inanimate carbon rod", "pillow", "airplane", "french bulldog"] def sentencemaker(): return random.choice(preamble) + ", I like to " + random.choice(action) + " " + random.choice(adjective) + " " + random.choice(noun) + "."
And you already know all this stuff too:
CONSUMER_KEY = 'Your Consumer Key' CONSUMER_SECRET = 'Your Consumer Secret' ACCESS_KEY = 'Your Access Token' ACCESS_SECRET = 'Your Access Token Secret' auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) auth.set_access_token(ACCESS_KEY, ACCESS_SECRET) api = tweepy.API(auth)
So now the fun begins. It all starts with a familiar infinite while loop, but then things get interesting:
while True:
twts = api.search(q="@LilPythonBaby", since_id=doneupto)
for t in twts:
if re.search("^@LilPythonBaby", t.text):
quoted = re.sub("^@LilPythonBaby ", "", t.text)
replyname = t.user.screen_name
reply = "@" + replyname + ' You say "' + quoted
if len(reply) > 122:
reply = reply[:119] + "..."
reply = reply + '" but I say "MEOW!"'
api.update_status(status=reply)
print reply
doneupto = t.id
f = open("doneupto.txt", "w")
f.write(str(doneupto))
f.close()
This is where the main action of checking for replies, formulating a reply, and sending a reply all happens. Let’s break that all down in greater detail.
twts = api.search(q="@LilPythonBaby", since_id=doneupto)
The above is one of those magical lines of Tweepy code where a ton of stuff happens. In the last example, we were only sending data to Twitter, namely stuff to post. This time we’re pulling data from Twitter, namely messages other people have written to us. In the above line, we’re asking Twitter to search for all messages matching a particular search term (or “query”). It will look for whatever we put after q=. Since I’m interested in Tweets that are being sent to my bot, my search term is my bot’s Twitter handle, @LilPythonBaby. So far so good. The next thing it does is very important. As discussed above in great detail, we want to make sure that Twitter only grabs messages we haven’t already replied to. So we also use the since_id parameter, and pass in the variable doneupto, which is where we store the ID of the latest message we’ve already replied to. So all in all, we’re saying “Give me every message matching the search term ‘@LilPythonBaby’, but only give me ones sent since the ID I’ve got stored in doneupto.”
Great. So once it has performed that search, it sticks its results into a variable called twts. The only thing we need to know about twts at this point is that it is ITERABLE in Python, and that it iterates over individual messages — so that if we got 5 messages, it would iterate over each of these 5 messages in turn, and we could reply to each one individually. That sounds good. So let’s start iterating! That’s what the next line of code does:
for t in twts:
As we iterate from tweet to tweet, the information contained in that tweet will be accessible via the variable name t (since that’s what we called it in the above line of code; we could have called it orangutan if we wanted to, and then the information would be accessible via the variable name organgutan).
Now Twitter returns a TON of information on each of the messages we received: it tells us the person who sent it to us, the contents of the message, the time it was sent, the GPS coordinates it was sent from (sometimes), how many followers and likes the person who sent it to us has, and all kinds of other useful stuff. So it’s important to think ahead and figure out what kinds of replies you want to send so that you can plan out what kind of data you actually want to pull out.
Here’s what I want to do. When someone sends an @-reply to @LilPythonBaby, I want my bot to reply, “You say ‘X,’ but I say ‘MEOW!'” (The conceit of my Twitter bot is that it’s my cat speaking. Long story.) X, in the above sample, is whatever the person wrote to my bot. So if someone with the Twitter handle @ahmmnd sent the following message, “@LilPythonBaby You are so cute and funny” I would want my bot to reply “@ahmmnd You say ‘You are so cute and funny’ but I say ‘MEOW!'”
To be able to do this, I need to be able to pull out two types of data from the message (in other words, from t): I need to know the Twitter handle of the person who sent the message, and I need to know the contents of that message. As it happens, accessing both of these is pretty easy. You can get the handle from t.user.screen_name and you can get the content of the message from t.text
You can get a sense of the many, many things you can grab from an individual message in the screen grab below, which shows how Python “sees” each tweet you receive. Notice that the content of the message (“@LilPythonBaby You should have won the Nobel Prize, not Bob Dylan.”) appears after text= in the screen shot, which corresponds to the way we access it (t.text). If you’re wondering what format that’s all it, it’s called JSON.
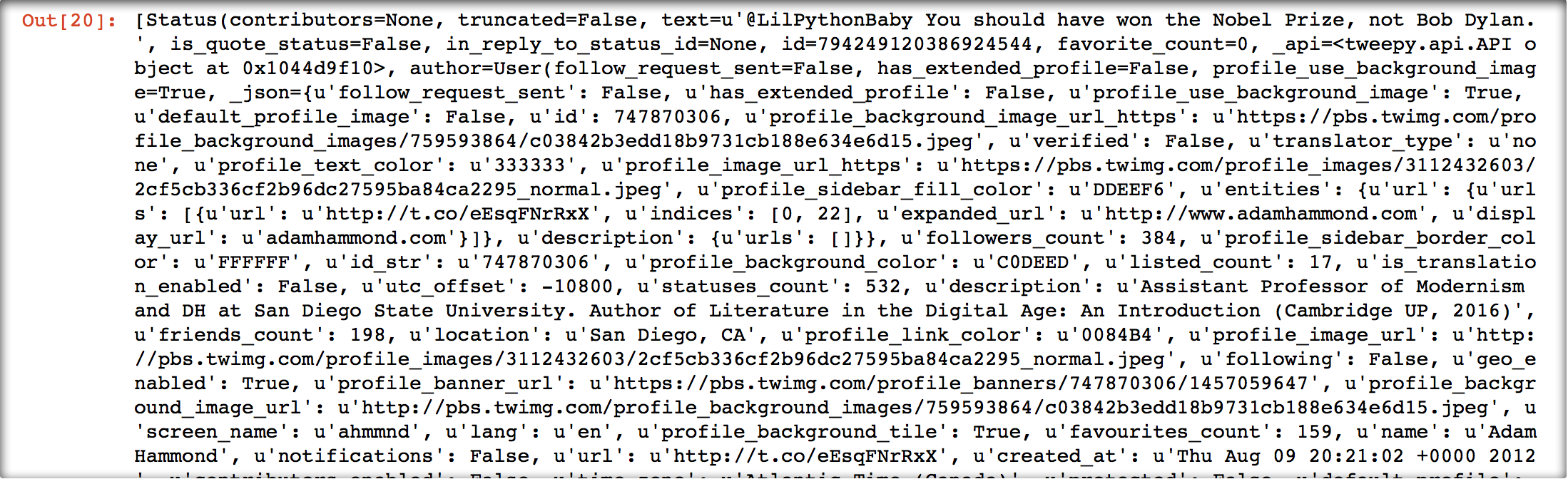
If you’re interested in pulling other kinds of information out of tweets, it’s time to head over to the Twitter API Developers page. Yep, you’re that hardcore now. You’re reading documentation written for Twitter Developers. Geez, I guess that makes you… a Twitter Developer!
Now that the heavy lifting is behind us, and we know what we want to do, let’s do it! Next line of code, please!
if re.search("^@LilPythonBaby", t.text):
In this line of code, I’m checking that the message in question (t.text) is an @-reply, and not just a message where @LilPythonBaby is mentioned. For now, I don’t want to do anything with mere mentions — but I do want to do something with @-replies. How do you tell an @-reply from a mention? Well, an @-reply always begins with the Twitter handle of the person the message is being sent to.
So what I need to do here is look at the content of the tweet (accessible through t.text) and see if it begins with @LilPythonBaby. This is a perfect time to use regular expressions, those glorious things that allow us to search for very specific text strings. If you care about literature and you’re interested in computing, regular expressions are your friends! Here, we use the re.search function to see if t.text contains the regular expression “^@LilPythonBaby” — and, you guessed it, the carat (^) is the regular expression way of saying “starts with.” Since this is all set up as an if statement, Python will check whether the tweet starts with @LilPythonBaby and, if it does, it will proceed to the next indentation level — and, if it doesn’t, it will just ignore the tweet. Which is exactly what we want it to do.
quoted = re.sub("^@LilPythonBaby ", "", t.text)
Now it’s time to grab some data and formulate our reply! In the above line, I grab the contents of the message sent to me (t.text), but I cut out the part that contains my bot’s Twitter handle. Since I don’t want to include my own name in my reply, it needs to go. Another regular expression function comes to the rescue here: re.sub takes t.text but substitutes my Twitter handle with nothing (“”). This nicely cleaned string is then fed into the variable quoted.
replyname = t.user.screen_name
This one’s a little easier: I just grab the Twitter handle of the person who sent me a message (accessible through t.user.screen_name) and stick it in the variable replyname.
reply = "@" + replyname + ' You say "' + quoted
Now I’m starting to actually formulate my reply! I’m doing so by sticking together a lot of strings and plopping them into a variable called reply. If I got the example tweet I mentioned above, reply would now contain ‘@ahmmnd You say “You are so cute and funny’
That’s only the first part of the tweet. I still want to add ‘” but I say “MEOW!”‘ to the end of that. But this is a good time to check if my reply is going to go over the ubiquitous Twitter 140 character limit. That bit I want to add (‘” but I say “MEOW!”‘) is 19 characters long. That means that the first part of my reply can’t be any longer than 121 characters (121 + 19 = 140). So if it’s longer, let’s lop off everything past character 118 and and add a nice dot dot dot (118 characters plus dot dot dot = 121 characters). That’s what the next lines do:
if len(reply) > 121:
reply = reply[:118] + "..."
Now that we’ve made sure we won’t exceed the Twitter character count, it’s time to finish our reply:
reply = reply + '" but I say "MEOW!"'
The value of reply is now exactly the message we want to send out: ‘@ahmmnd You say “You are so cute and funny” but I say “MEOW!”‘ So let’s send it out! That’s done in a way that is already familiar:
api.update_status(status=reply)
So we’re done! Right? We’ve (a) looked through all the messages we’ve received, (b) made sure they’re actually @-replies and not just mentions, (c) pulled out the data we needed and formulated a reply, and (d) sent out the reply. But there’s one more crucial thing we need to do before we can punch out for the day. We need to record the ID of the tweet we’ve just replied to, so we don’t accidentally reply to it again. And since we want to be really sure we never reply to this message again, we’re not just going to store the ID in a variable, we’re actually going to write it to our hard drive.
Luckily, it’s easy to pull out the tweet ID: you just use t.id
Writing the contents of t.id to the disk is pretty easy too, and familiar from the process at the beginning of this script where we did the reverse and imported a number from a file. It’s the following:
doneupto = t.id
f = open("doneupto.txt", "w")
f.write(str(doneupto))
f.close()
First, it records the tweet ID in the variable doneupto. Then it opens the file doneupto.txt in “write” (“w”) mode, which means it will just write over whatever that file currently contains — which is good, since we all we care about is the ID of the last message we’ve replied to, not the IDs of all the messages we’ve ever replied to. Then it converts doneupto into a string and writes it to the disk, and finally closes the file.
Everything else is familiar from the last section: it generates a tweet, posts it to Twitter, and waits for an hour before beginning the whole process (checking, replying, posting) all over again. Such too will be the bare Sisyphean existence of your poor Twitter bot. But at least, if you’ve done your job right, it’ll make some good jokes along the way.
5. The Gysinner Bot
Originally, when I sat down to write this tutorial (about, oh, eight hours ago!), I had planned to conclude with a flourish by explaining how I made my @Gysinner bot. That seems way too ambitious now. But I will at least explain what it does, and post in my code so that you can have a look and try to figure it out.
This bot is based on one of the earliest experiments in computational literature, the “Permutation Poems” devised by Brion Gysin and Ian Sommerville in the early 1960s. Brion Gysin is just one of the coolest people to have lived in the 20th century. A short-lived member of the Paris Surrealist Group, a friend of the Bowleses in Tangier, and a resident of the Beat Hotel in Paris again in the late fifties, when he invented the cut-up technique and passed it on to Burroughs. He’s also Canadian by birth, which doesn’t hurt. And, in the midst of doing all this, he also collaborated with Sommerville — another resident of the Beat Hotel — to make some of the earliest computational poetry.
My @Gysinner bot is based on their Permutation Poems. You can see a nice recreation of their poems in this YouTube video (which also contains a link, in the description, to a GitHub page containing the software’s Python code). Basically, a Permutation Poem takes a phrase and rearranges the words in every possible way. With a phrase like “I AM THAT I AM,” the results can be pretty profound. With a phrase like “ME IS SO HUNGRY FOR COOKIE,” the results can be pretty hilarious.
I wanted to make a Gysin-inspired bot that would do the following. If someone sends it an @-reply, it takes the contents of this message (minus the @Gysinner Twitter handle) and begins “permutating” that phrase. It then keeps on permutating this phrase until it receives another @-reply, at which point it drops the previous phrase and starts permutating the new one. If it only ever receives one @-reply, it just keeps permutating that one phrase forever. Speaking of Sisyphus.
Mine isn’t strictly a Gysin-and-Somerville-like script. Rather than offer every single possibility, in order, mine just shuffles the words randomly every time it posts. So there is no strict order to what’s happening there. The main function is as follows:
def gysin(phrase):
phrase = phrase.upper()
phrase = phrase.split()
random.shuffle(phrase)
return ' '.join(phrase)
That just takes a phrase, uppercases it (Gysin-style!), splits it into individual words, shuffles those words, and then joins the words back together in their shuffled order.
Incidentally, if you wanted to produce a nice, ordered list of all the possible ways of reordering the words in a phrase — more like the original Gysin/Somerville script — you could use this function instead:
import itertools, random
def gysin2(phrase):
phrase = phrase.split()
gysinned = list(itertools.permutations(phrase))
nicelist = []
for item in gysinned:
newline = ' '.join(item)
nicelist = nicelist + [newline]
return nicelist
Most of the work is done by a built-in module called itertools, but it returns data in a format I don’t like, so most of the work there is putting its output into a simpler list of strings. There might be a snazzier way of accomplishing this, but I’m pretty happy to be able to recreate a landmark of literary programming in a few simple lines and understand what’s happening at every step.
By the way, it also makes me pretty happy that the itertools function that shows all permutations of a particular list is called… itertools.permutations(). Someone knows their literary history in the Python development team.
Anyway, as I said, I’m not going to explain this code, because it’s really very similar to the previous example. So I’ll just post it below and let you try to figure it out. The actual working version of the bot (which you can play with by sending @-replies to @Gysinner) does three things that the below code doesn’t:
- It sticks randomly-chosen emojis into messages, partially for fun, but mostly to get around Twitter’s insistence on refusing any duplicate messages. (During testing, it was sending a lot of the following message: “@ahmmnd Thanks for the idea. I am Gysinning that now.”)
- It filters out messages with hateful or especially profane messages. (I don’t want my peaceful bot spewing hate… especially not this week.)
- In addition to sending a “Thanks for the idea” @-reply to people who inspire it, it also apologizes to previous inspirers when it moves on to a new inspiration.
But here are the basics:
import random, tweepy, re, time
def gysin(phrase):
phrase = phrase.upper()
phrase = phrase.split()
random.shuffle(phrase)
return ' '.join(phrase)
# this is how I make sure I don't reply to tweets I've already replied to:
f = open("doneuptogysin.txt","r")
doneuptogysin = f.read()
doneuptogysin = int(doneuptogysin)
f.close()
# this is how I store the current phrase I'm Gysinning so I don't have to
# start from scratch when it crashes
f = open("gysinseed.txt","r")
seed = f.read()
f.close()
# connecting to Twitter with Tweepy
CONSUMER_KEY = 'Your Consumer Key'
CONSUMER_SECRET = 'Your Consumer Secret'
ACCESS_KEY = 'Your Access Token'
ACCESS_SECRET = 'Your Access Token Secret'
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_SECRET)
api = tweepy.API(auth)
# all the main magic
while True:
twts = api.search(q="@Gysinner", since_id=doneuptogysin)
for t in twts:
if re.search("^@Gysinner", t.text):
seed = re.sub("^@Gysinner ", "", t.text)
f = open("gysinseed.txt", "w")
f.write(seed)
f.close()
replyname = t.user.screen_name
reply = "@" + replyname + ' Thanks for the idea. I am Gysinning that now.'
if len(reply) <= 140:
api.update_status(status=reply)
print reply
time.sleep(2)
doneuptogysin = t.id
f = open("doneuptogysin.txt", "w")
f.write(str(doneuptogysin))
f.close()
postthis = gysin(seed)
if len(postthis) <= 140:
api.update_status(status=postthis)
print postthis
time.sleep(120)
So there you have it. Some instructions, some examples, some code — everything you need to go out and make a real, live Twitter bot. Have fun — and if you come up with something great, tell me (@ahmmnd) about it. Or at least tell my bots. @LilPythonBaby and @Gysinner are dying to hear from you.